Data Autonomy - Case Study

- Semprini
- Aug. 5, 2020
- 0
A couple of contracts back I was consulting as a solution architect at a national retail organisation. I ran an experiment as a proof of the cadence which is possible using Data Autonomy.
Shortly after the project went live, I decided to build it again myself using the concepts of Data Autonomy as realistically as possible. The result was a far better solution in a third of the time & cost.
The Project
The project which I was brought on to deliver was a loyalty platform. The project was run as a pretty standard iterative waterfall - so there was relatively fixed cost and outcomes. The budget was $700,000 and the time-frame was 6 months, both of which we met.
In a loyalty system, events (like Sales, Payments etc) need to accrue a value onto a customers loyalty balance. Quite often, as in this case, the balance is held by a 3rd party rewards provider. We need to calculate the loyalty accrual, tell the provider how much to give each customer and give the value of the loyalty to the provider to allow the customer to redeem to the value.
The Implemented High-Level Solution
I was constrained in the solution by legacy systems, legacy processes and legacy architecture so it consisted of:
- Batches of sale data uploaded daily from the stores
- An IBM AS400 loaded the files
- The AS400 calculated loyalty for the batch
- A daily report was extracted
- The daily report was sent to an external loyalty provider company
- A daily response file was returned by loyalty provider with result and errors
- The response file was loaded into the finance general ledger
- The errors were loaded into the AS400 and email report sent to stores and support
Data Autonomy High Level Solution

To be as complete and realistic as possible I included the following:
- Automated regression
- Infrastructure as code
- Containerization
- CI/CD pipelines
- Micro-services
- Model Driven Generation
to optimise delivery, the following were omitted :
- External IDP. I have subsequently done this using Azure AD and ABAC controls.
- Change Advisory Board (CAB)
- User & operational training
Data Product Solution
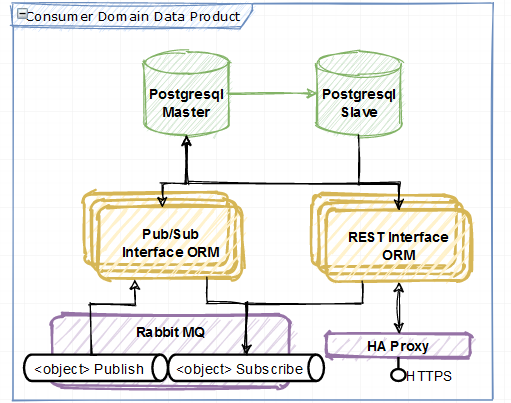
Key to data autonomy is realization of one or more (business domain based) standard data models which is then exposed via RESTful APIs and a message broker. Since this was retail and the organisation had some experience with the PCF for retail framework this is where I started but soon introduced the party/party role concepts from many industry standard data models like TM Forum/IAA etc. BTW, this convergence of models is what spurred me to create CBE - Common Business Entities.
- Modelling was done in UML using Sparx EA and a parser found here: pyMDG.
- The output from this was pushed to the CI pipeline to generate a django application with django-rest-framework and pika
- Database migrations were created - automated if possible but with a manual step if needed to enable small, regular changes.
- Docker, docker compose and Rancher was used to deliver orchestrated containers:
- Postgres in master-slave mode
- HAProxy
- Django application with auto-scaling
- RabbitMQ cluster
- Prometheus
- Graphana
- Hosted Kubernetes was still new so AWS VMs hosted the solution and were themselves orchestrated using CDAF
- The Atlassian stack was used for CI & CD
It is notable that this data solution is for a holistic data platform for all significant business objects of the business. Thus, the overhead of creating it is a once-off and data can simply be added to it as the data architecture of future projects identify significant business objects.
We could now GET/POST/PUT/PATCH and publish/subscribe to changes for all significant business objects involved in loyalty. These objects included things like Sale, Account, Customer, Person so by having these objects available we have now unlocked many solutions - see the proofs below.
I have run performance testing for this setup on very moderate infrastructure (circa $2k per month) at over 18,000 Sale objects per second. (using POST of a list of Sales). The solution will hold to more than 100,000 per second moving cloud native for Kubernetes, AWS Aurora and Kafka.
Micro-services
This is where the business logic is implemented. I created a queue trigger pattern enterprise micro-service:
Loyalty Accrual Micro-Service - PCF level 4 scope ( Level 4 = A key step performed to execute a process)
- Cached all Customer and LoyaltyMembership objects on startup
- Subscribed to Customer, LoyaltyMembership and Sale object events
- Customer and LoyaltyMembership object updates kept the cache in-sync
- Sale object changes used a status routing key to filter only non-accrued sales
- Sale was matched to customer
- API at loyalty provider was called to update customers loyalty balance
- A LoyaltyAccrual object was POSTed to the data platform
- The Sale object status was PATCHed to the data platform
- Retryable errors used a retry queue and unrecoverable errors used a dead letter queue which can raise a support ticket. This was included in the micro-service pattern boilerplate so the micro-service code just needed to raise a retryable or non-retryable error.
Another, serverless (AWS lambda) utility micro-service was created to pick up the batch files created by each store and POST Sale, Customer and LoyaltyMembership objects to the data platform.
A final queue trigger pattern micro-service subscribed to the LoyaltyAccrual object and created the batch of financial transactions that the accounting system required.
Summary Findings
The micro-services ran for cents per day and the entire solution for a few thousand dollars a month. This is a huge display of how separating business logic from data persistence and access on cloud native solutions deliver huge savings combined with limiting dependencies for massive sustained increase in delivery cadence.
The data autonomy based solution took 2 months spare time to design and implement but most of this time was for the holistic data platform so would not need to be built again. It was also built to be good at data change and evolution - model, governance and scale.
Because of Data Autonomy the business is now dependent on the LoyaltyAccrual object (I.e. business semantics) and not dependent on an application. We know that something will create the object because that's how the retail organisation works but we don't care what creates it and we have a range of options to get or subscribe based on how each consumer works best. This is much better loose coupling than pure integration architectures provide.
As a proof of data autonomy unlocking opportunity, I created a micro-service which subscribed to sales on account and called a Xero web-service which created an invoice on a customers accounting package and then PATCHed the 'invoiced' status back to the data platform. This took a couple of days for production ready code to be delivered - with full automated regression. The cadence of delivery was incredible.
I'll be writing some more on the process to create data platforms with no coding from models.



Comments (0)
No comments yet. Be the first!
Log in to leave a comment.